publications
* indicates equal contribution among authors
† indicates co-corresponding authors
2026
-
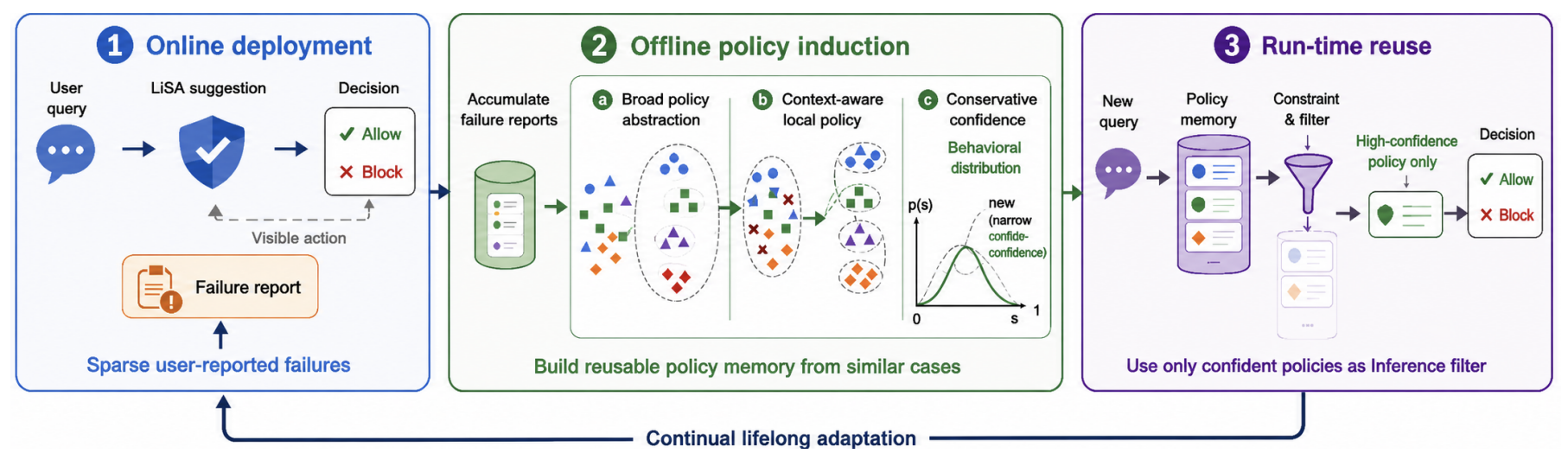 LiSA: Lifelong Safety Adaptation via Conservative Policy InductionMinbeom Kim, Lesly Miculicich , Bhavana Dalvi Mishra , Mihir Parmar , Phillip Wallis , Bharath Chandrasekhar , Kyomin Jung , Tomas Pfister , and Long T. Learxiv 2026
LiSA: Lifelong Safety Adaptation via Conservative Policy InductionMinbeom Kim, Lesly Miculicich , Bhavana Dalvi Mishra , Mihir Parmar , Phillip Wallis , Bharath Chandrasekhar , Kyomin Jung , Tomas Pfister , and Long T. Learxiv 2026As AI agents move from chat interfaces to systems that read private data, call tools, and execute multi-step workflows, guardrails become a last line of defense against concrete deployment harms. In these settings, guardrail failures are no longer merely answer-quality errors: they can leak secrets, authorize unsafe actions, or block legitimate work. The hardest failures are often contextual: whether an action is acceptable depends on local privacy norms, organizational policies, and user expectations that resist pre-deployment specification. This creates a practical gap: guardrails must adapt to their own operating environments, yet deployment feedback is typically limited to sparse, noisy user-reported failures, and repeated fine-tuning is often impractical. To address this gap, we propose LiSA (Lifelong Safety Adaptation), a conservative policy induction framework that improves a fixed base guardrail through structured memory. LiSA converts occasional failures into reusable policy abstractions so that sparse reports can generalize beyond individual cases, adds conflict-aware local rules to prevent overgeneralization in mixed-label contexts, and applies evidence-aware confidence gating via a posterior lower bound, so that memory reuse scales with accumulated evidence rather than empirical accuracy alone. Across PrivacyLens+, ConFaide+, and AgentHarm, LiSA consistently outperforms strong memory-based baselines under sparse feedback, remains robust under noisy user feedback even at 20% label-flip rates, and pushes the latency–performance frontier beyond backbone model scaling. Ultimately, LiSA offers a practical path to secure AI agents against the unpredictable long tail of real-world edge risks.
-
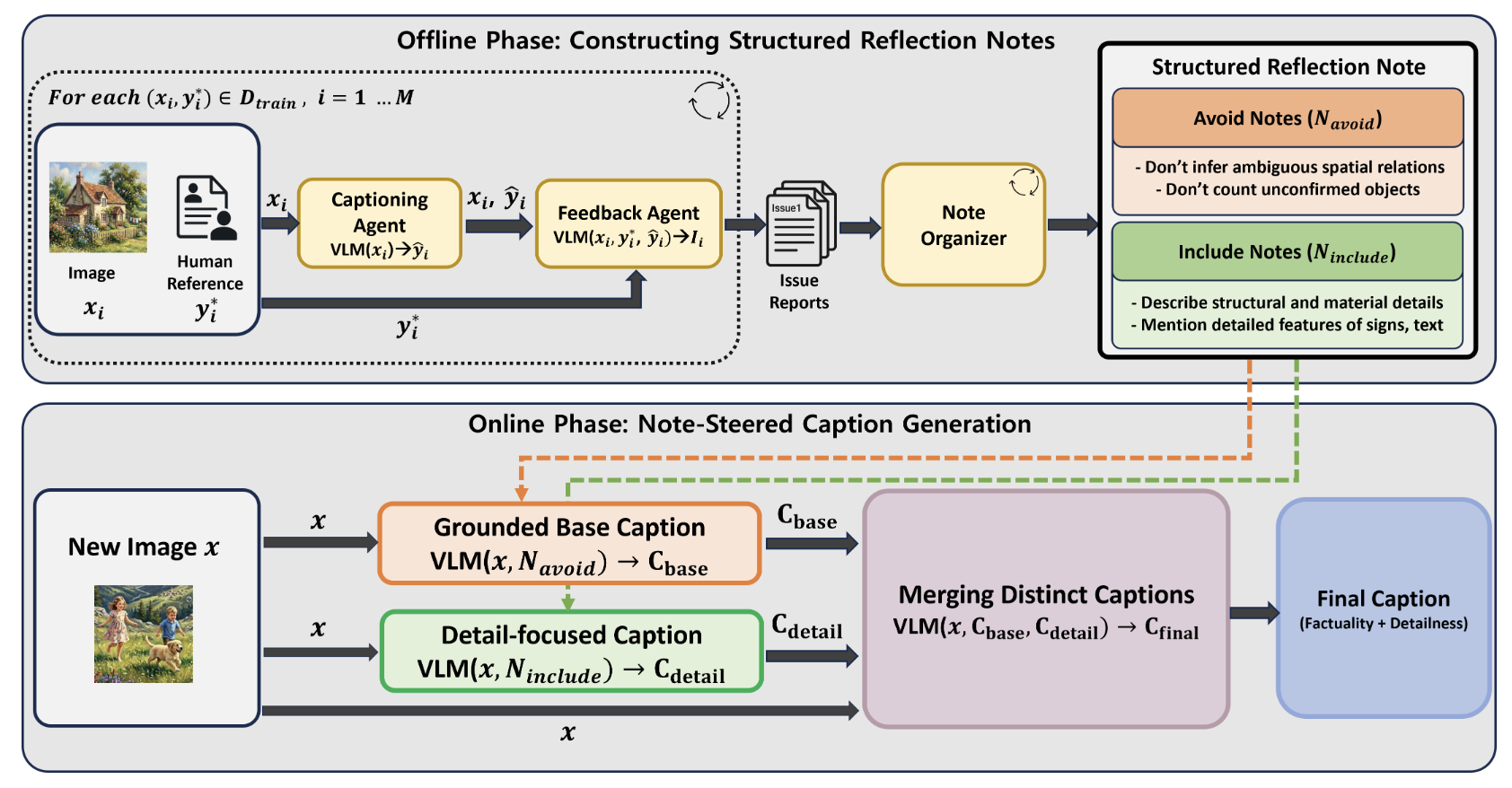 ReflectCAP: Detailed Image Captioning with Reflective MemoryKyungmin Min , Minbeom Kim, Kang-il Lee , Seunghyun Yoon , and Kyomin JungECCV 2026
ReflectCAP: Detailed Image Captioning with Reflective MemoryKyungmin Min , Minbeom Kim, Kang-il Lee , Seunghyun Yoon , and Kyomin JungECCV 2026Detailed image captioning demands both factual grounding and fine-grained coverage, yet existing methods have struggled to achieve them simultaneously. We address this tension with Reflective Note-Guided Captioning (ReflectCAP), where a multi-agent pipeline analyzes what the target large vision-language model (LVLM) consistently hallucinates and what it systematically overlooks, distilling these patterns into reusable guidelines called Structured Reflection Notes. At inference time, these notes steer the captioning model along both axes—what to avoid and what to attend to—yielding detailed captions that jointly improve factuality and coverage. Applying this method to 8 LVLMs spanning the GPT-4.1 family, Qwen series, and InternVL variants, ReflectCAP reaches the Pareto frontier of the trade-off between factuality and coverage, and delivers substantial gains on CapArena-Auto, where generated captions are judged head-to-head against strong reference models. Moreover, ReflectCAP offers a more favorable trade-off between caption quality and compute cost than model scaling or existing multi-agent pipelines, which incur 21–36% greater overhead. This makes high-quality detailed captioning viable under real-world cost and latency constraints.
-
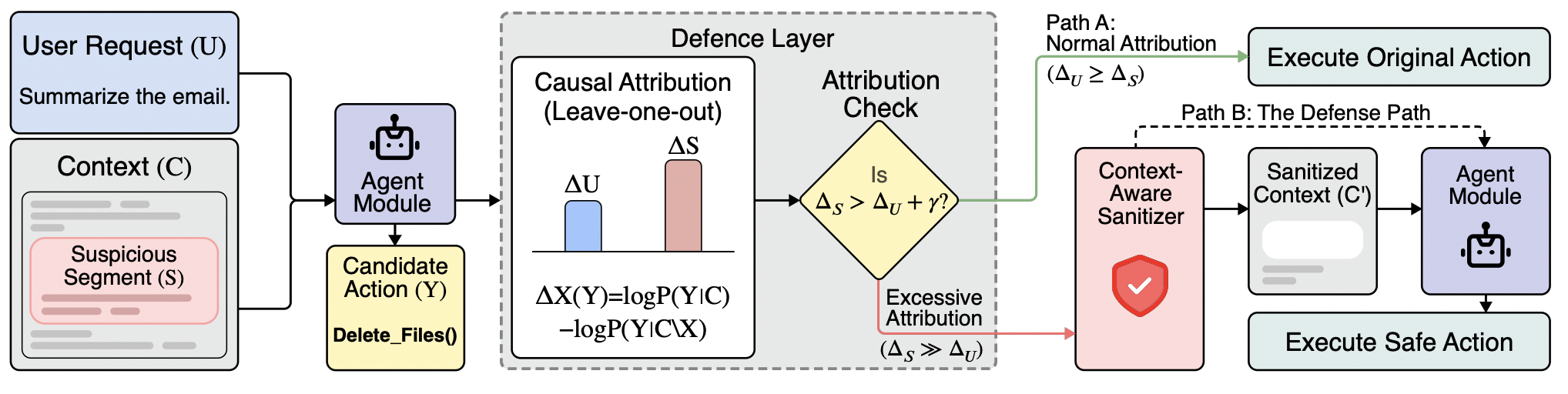 CausalArmor: Efficient Indirect Prompt Injection Guardrails via Causal AttributionMinbeom Kim, Mihir Parmar , Phillip Wallis , Lesly Miculicich , Kyomin Jung , Krishnamurthy Dj Dvijotham , Long T. Le , and Tomas PfisterICML 2026
CausalArmor: Efficient Indirect Prompt Injection Guardrails via Causal AttributionMinbeom Kim, Mihir Parmar , Phillip Wallis , Lesly Miculicich , Kyomin Jung , Krishnamurthy Dj Dvijotham , Long T. Le , and Tomas PfisterICML 2026AI agents equipped with tool-calling capabilities are susceptible to Indirect Prompt Injection (IPI) attacks. In this attack scenario, malicious commands hidden within untrusted content trick the agent into performing unauthorized actions. Existing defenses can reduce attack success but often suffer from the over-defense dilemma: they deploy expensive, always-on sanitization regardless of actual threat, thereby degrading utility and latency even in benign scenarios. We revisit IPI through a causal ablation perspective: a successful injection manifests as a dominance shift where the user request no longer provides decisive support for the agent’s privileged action, while a particular untrusted segment, such as a retrieved document or tool output, provides disproportionate attributable influence. Based on this signature, we propose CausalArmor, a selective defense framework that (i) computes lightweight, leave-one-out ablation-based attributions at privileged decision points, and (ii) triggers targeted sanitization only when an untrusted segment dominates the user intent. Additionally, CausalArmor employs retroactive Chain-of-Thought masking to prevent the agent from acting on “poisoned” reasoning traces. We present a theoretical analysis showing that sanitization based on attribution margins conditionally yields an exponentially small upper bound on the probability of selecting malicious actions. Experiments on AgentDojo and DoomArena demonstrate that CausalArmor matches the security of aggressive defenses while improving explainability and preserving utility and latency of AI agents.
-
 Beyond Normalization: Rethinking the Partition Function as a Difficulty Scheduler for RLVRDohyung Kim , Minbeom Kim, Jeonghye Kim , Sangmook Lee , Sojeong Rhee , and Kyomin JungICML 2026
Beyond Normalization: Rethinking the Partition Function as a Difficulty Scheduler for RLVRDohyung Kim , Minbeom Kim, Jeonghye Kim , Sangmook Lee , Sojeong Rhee , and Kyomin JungICML 2026Reward-maximizing RL methods enhance the reasoning performance of LLMs, but often reduce the diversity among outputs. Recent works address this issue by adopting GFlowNets, training LLMs to match a target distribution while jointly learning its partition function. In contrast to prior works that treat this partition function solely as a normalizer, we reinterpret it as a per-prompt expected-reward (i.e., online accuracy) signal, leveraging this unused information to improve sample efficiency. Specifically, we first establish a theoretical relationship between the partition function and per-prompt accuracy estimates. Building on this key insight, we propose Partition Function-Guided RL (PACED-RL), a post-training framework that leverages accuracy estimates to prioritize informative question prompts during training, and further improves sample efficiency through an accuracy estimate error-prioritized replay. Crucially, both components reuse information already produced during GFlowNet training, effectively amortizing the compute overhead into the existing optimization process. Extensive experiments across diverse benchmarks demonstrate strong performance improvements over GRPO and prior GFlowNet approaches, highlighting PACED-RL as a promising direction for a more sample efficient distribution-matching training for LLMs.
-
 Are We Measuring Strategy or Phrasing? The Gap Between Surface- and Approach-Level Diversity in LLM Math ReasoningSangmook Lee , Minbeom Kim, Jeonghye Kim , Dohyung Kim , Sojeong Rhee , and Kyomin JungICML 2026 AI4Math (Spotlight, Top 2.9%)
Are We Measuring Strategy or Phrasing? The Gap Between Surface- and Approach-Level Diversity in LLM Math ReasoningSangmook Lee , Minbeom Kim, Jeonghye Kim , Dohyung Kim , Sojeong Rhee , and Kyomin JungICML 2026 AI4Math (Spotlight, Top 2.9%)Diversity in LLM mathematical reasoning is critical for exploration, but common diversity metrics mostly capture \textitsurface-level variation rather than differences in how a problem is solved. We address this gap by introducing \textbfapproach-level diversity: variation in strategies across correct solutions to the same problem. Using a human-calibrated LLM judge framework, we show that prior diversity measures are unreliable proxies for approach-level diversity, and this mismatch carries over to diversity-aware RLVR, where target metrics are preserved while approach-level diversity declines. Investigating when approach-level diversity helps and whether it can be directly induced, we find that approach-diverse candidate sets improve test-time scaling. However, optimizing an LLM judge diversity reward during training causes the policy to exploit judge-specific preferences rather than broaden its approaches, leaving direct optimization of approach-level diversity as an open problem. Together, our work introduces the notion of approach-level diversity and uncovers a systematic divergence between surface- and approach-level signals, marking a step toward LLMs that reason in genuinely diverse, human-like ways.
-
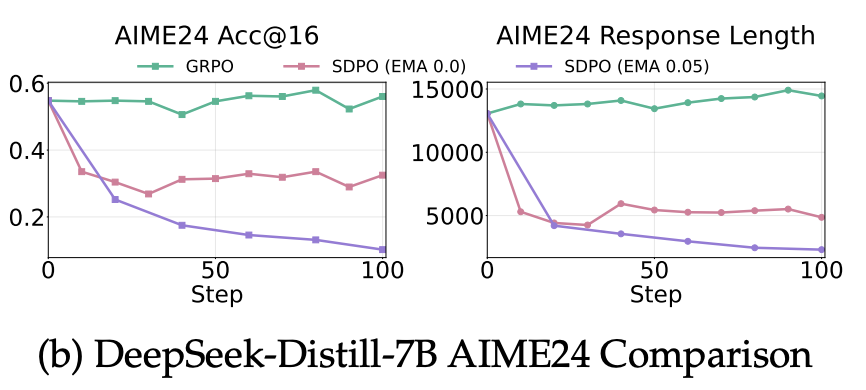 Why Does Self-Distillation (Sometimes) Degrade the Reasoning Capability of LLMs?Jeonghye Kim , Xufang Luo , Minbeom Kim, Sangmook Lee , Dohyung Kim , Jiwon Jeon , Dongsheng Li , and Yuqing Yangarxiv 2026
Why Does Self-Distillation (Sometimes) Degrade the Reasoning Capability of LLMs?Jeonghye Kim , Xufang Luo , Minbeom Kim, Sangmook Lee , Dohyung Kim , Jiwon Jeon , Dongsheng Li , and Yuqing Yangarxiv 2026Self-distillation has emerged as an effective post-training paradigm for LLMs, often improving performance while shortening reasoning traces. However, in mathematical reasoning, we find that it can reduce response length while degrading performance. We trace this degradation to the suppression of epistemic verbalization - the model’s expression of uncertainty during reasoning. Through controlled experiments varying conditioning context richness and task coverage, we show that conditioning the teacher on rich information suppresses uncertainty expression, enabling rapid in-domain optimization with limited task coverage but harming OOD performance, where unseen problems benefit from expressing uncertainty and adjusting accordingly. Across Qwen3-8B, DeepSeek-Distill-Qwen-7B, and Olmo3-7B-Instruct, we observe performance drops of up to 40%. Our findings highlight that exposing appropriate levels of uncertainty is crucial for robust reasoning and underscore the importance of optimizing reasoning behavior beyond merely reinforcing correct answer traces.
-
 Understanding Reasoning in LLMs through Strategic Information Allocation under UncertaintyJeonghye Kim , Xufang Luo , Minbeom Kim, Sangmook Lee , DongSheng Li , and Yuqing Yangarxiv 2026
Understanding Reasoning in LLMs through Strategic Information Allocation under UncertaintyJeonghye Kim , Xufang Luo , Minbeom Kim, Sangmook Lee , DongSheng Li , and Yuqing Yangarxiv 2026LLMs often exhibit Aha moments during reasoning, such as apparent self-correction following tokens like "wait," yet their underlying mechanisms remain unclear. We introduce an information-theoretic framework that decomposes reasoning into procedural information and epistemic verbalization—the explicit externalization of uncertainty that supports downstream control actions. We show that purely procedural reasoning can become informationally stagnant, whereas epistemic verbalization enables continued information acquisition and is critical for achieving information sufficiency. Empirical results demonstrate that strong reasoning performance is driven by uncertainty externalization rather than specific surface tokens. Our framework unifies prior findings on Aha moments and post-training experiments, and offers insights for future reasoning model design.







2025
-
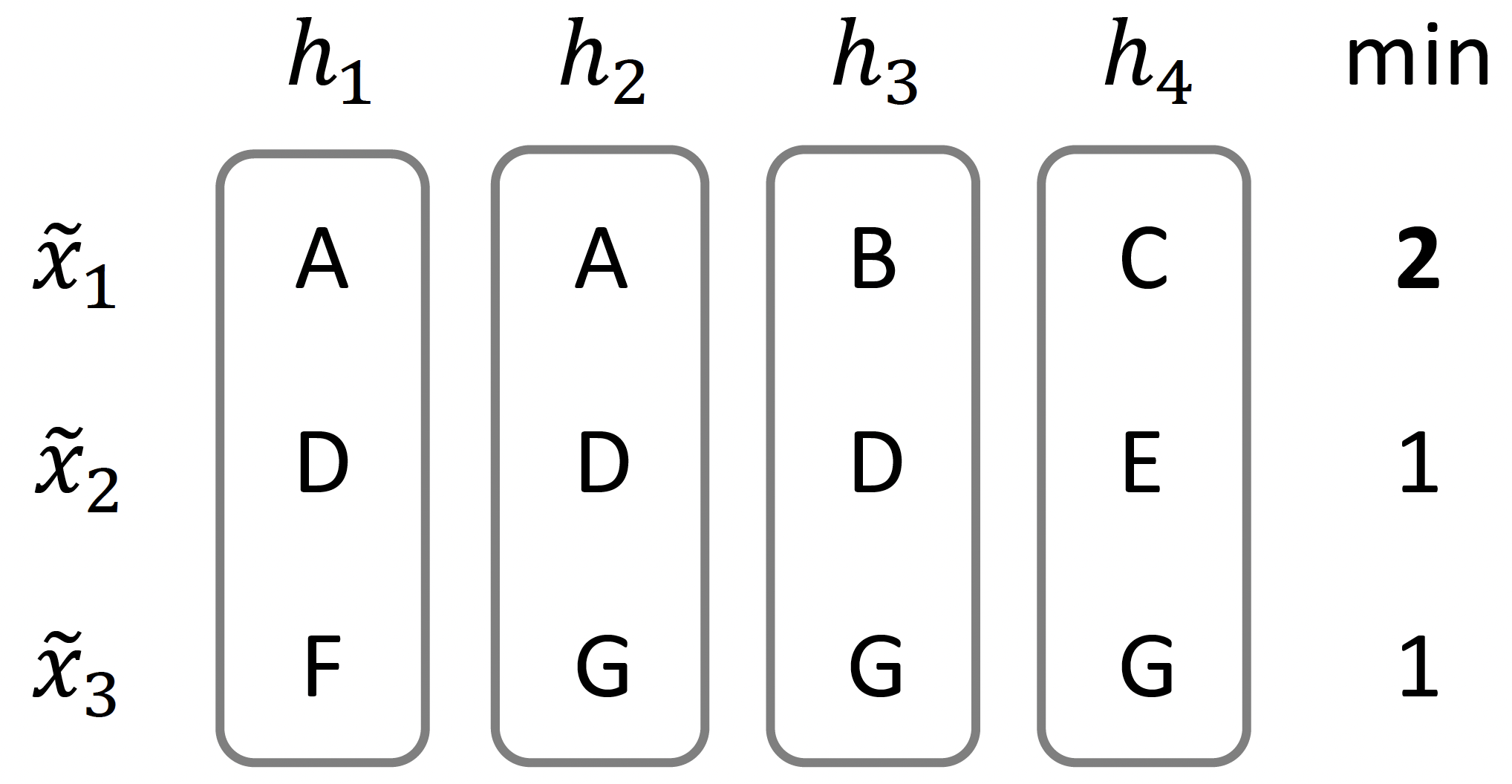 Program Synthesis via Test-Time TransductionKang-il Lee , Jahyun Koo , Seunghyun Yoon , Minbeom Kim, Hyukhun Koh , Dongryeol Lee , and Kyomin JungNeurIPS 2025
Program Synthesis via Test-Time TransductionKang-il Lee , Jahyun Koo , Seunghyun Yoon , Minbeom Kim, Hyukhun Koh , Dongryeol Lee , and Kyomin JungNeurIPS 2025We introduce transductive program synthesis, a new formulation of the program synthesis task that explicitly incorporates access to test inputs during synthesis. While prior approaches to program synthesis—whether based on natural language descriptions or input-output examples—typically aim to generalize from training examples, they often struggle with robustness, especially in real-world settings where training examples are limited and test inputs involve various edge cases. To address this, we propose a novel framework that improves robustness by treating synthesis as an active learning over a finite hypothesis class defined by programs’ outputs. We use an LLM to predict outputs for selected test inputs and eliminate inconsistent hypotheses, where the inputs are chosen via a greedy maximin algorithm to minimize the number of LLM queries required. We evaluate our approach on two real-world datasets: Playgol, a string transformation benchmark, and MBPP+, a Python code generation benchmark. We demonstrate that our method significantly improves program synthesis in both accuracy and efficiency.
-
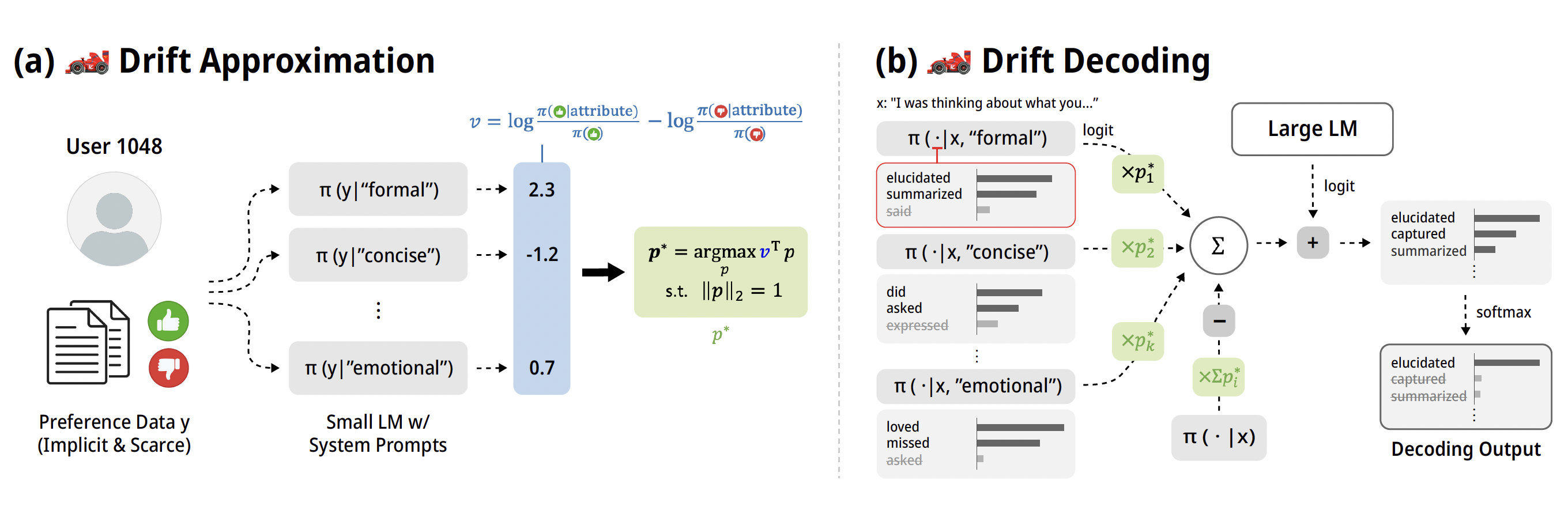 🏎️ Drift: Decoding-time Personalized Alignments with Implicit User PreferencesMinbeom Kim, Kang-il Lee , Seongho Joo , Hwaran Lee , Thibaut Thonet , and Kyomin JungEMNLP 2025
🏎️ Drift: Decoding-time Personalized Alignments with Implicit User PreferencesMinbeom Kim, Kang-il Lee , Seongho Joo , Hwaran Lee , Thibaut Thonet , and Kyomin JungEMNLP 2025Personalized alignments towards individual users have been a long-standing goal in large language models (LLMs). We introduce Drift, a novel framework that personalizes LLMs at decoding-time with implicit user preferences. Unlike traditional Reinforcement Learning from Human Feedback (RLHF), which relies on vast annotated datasets and expensive gradient updates, Drift operates in a training-free manner by steering a frozen LLM through few-shot preference modeling. Our approach represents user preferences as a composition of interpretable and predefined attributes, and employs a zero-shot rewarding mechanism based on contrastive system prompts. Experiments on both a synthetic persona dataset (Perspective) and a real human-annotated dataset (PRISM) demonstrate that Drift achieves performance comparable to standard RLHF methods while using only 50–100 examples. Our results and analysis show that Drift is both computationally efficient and interpretable.
-
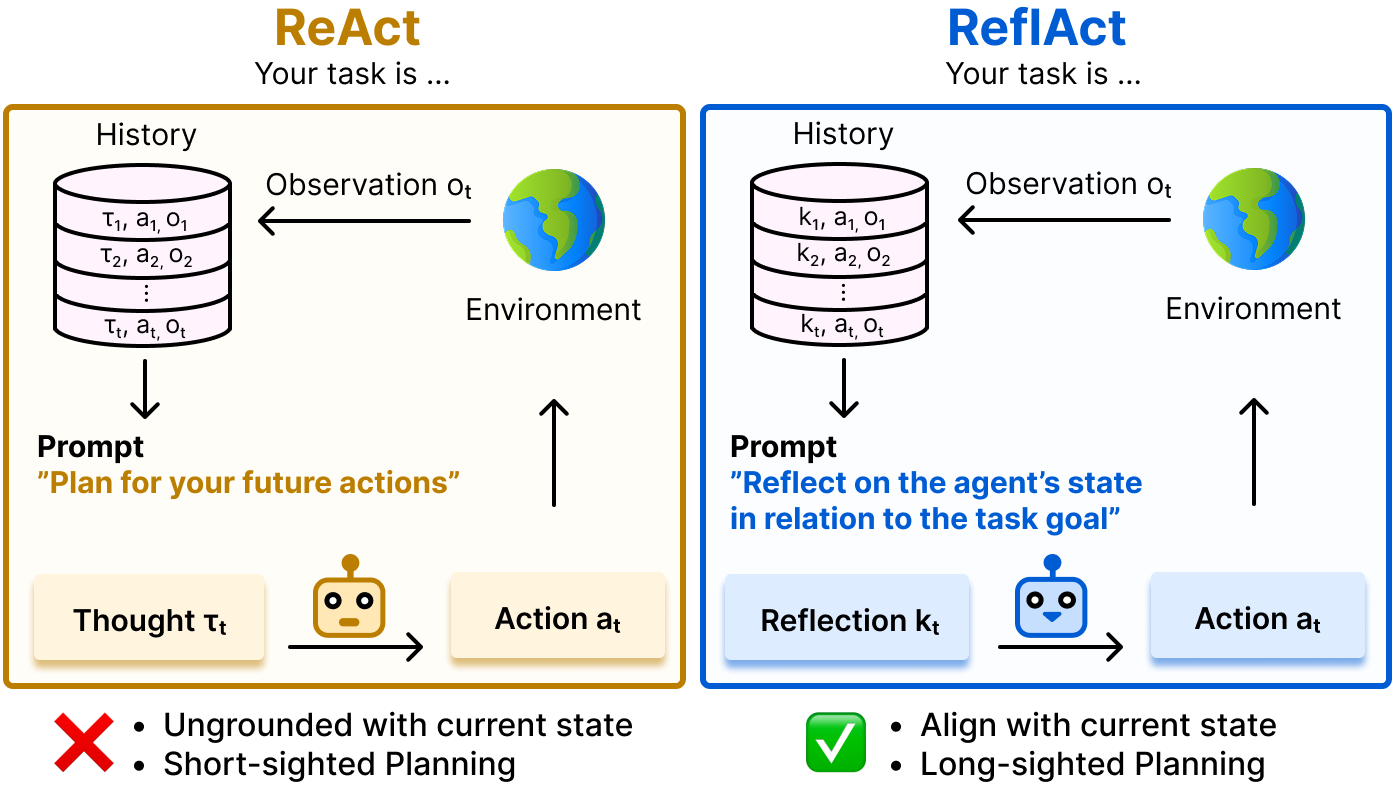 ReflAct: World-Grounded Decision Making in LLM Agents via Goal-State ReflectionJeonghye Kim* , Sojeong Rhee* , Minbeom Kim, Dohyung Kim , Sangmook Lee , Youngchul Sung† , and Kyomin Jung†EMNLP 2025
ReflAct: World-Grounded Decision Making in LLM Agents via Goal-State ReflectionJeonghye Kim* , Sojeong Rhee* , Minbeom Kim, Dohyung Kim , Sangmook Lee , Youngchul Sung† , and Kyomin Jung†EMNLP 2025Recent advances in LLM agents have largely built on reasoning backbones like ReAct, which interleave thought and action in complex environments. However, ReAct often produces ungrounded or incoherent reasoning steps, leading to misalignment between the agent’s actual state and goals. Our analysis finds that this stems from ReAct’s inability to maintain consistent internal beliefs and goal alignment, causing compounding errors and hallucinations. To address this, we introduce ReflAct, a novel backbone that shifts reasoning from merely planning next actions to continuously reflecting on the agent’s state relative to its goals. By explicitly grounding decisions in states and enforcing ongoing goal alignment, ReflAct dramatically improves strategic reliability. This design delivers substantial empirical gains: ReflAct surpasses ReAct by 24.9% on average, achieving a 93.3% success rate in ALFWorld. Notably, ReflAct even outperforms ReAct with added enhancement modules (e.g., Reflexion, WKM), showing that strengthening the core reasoning backbone is key to reliable agent performance.
-
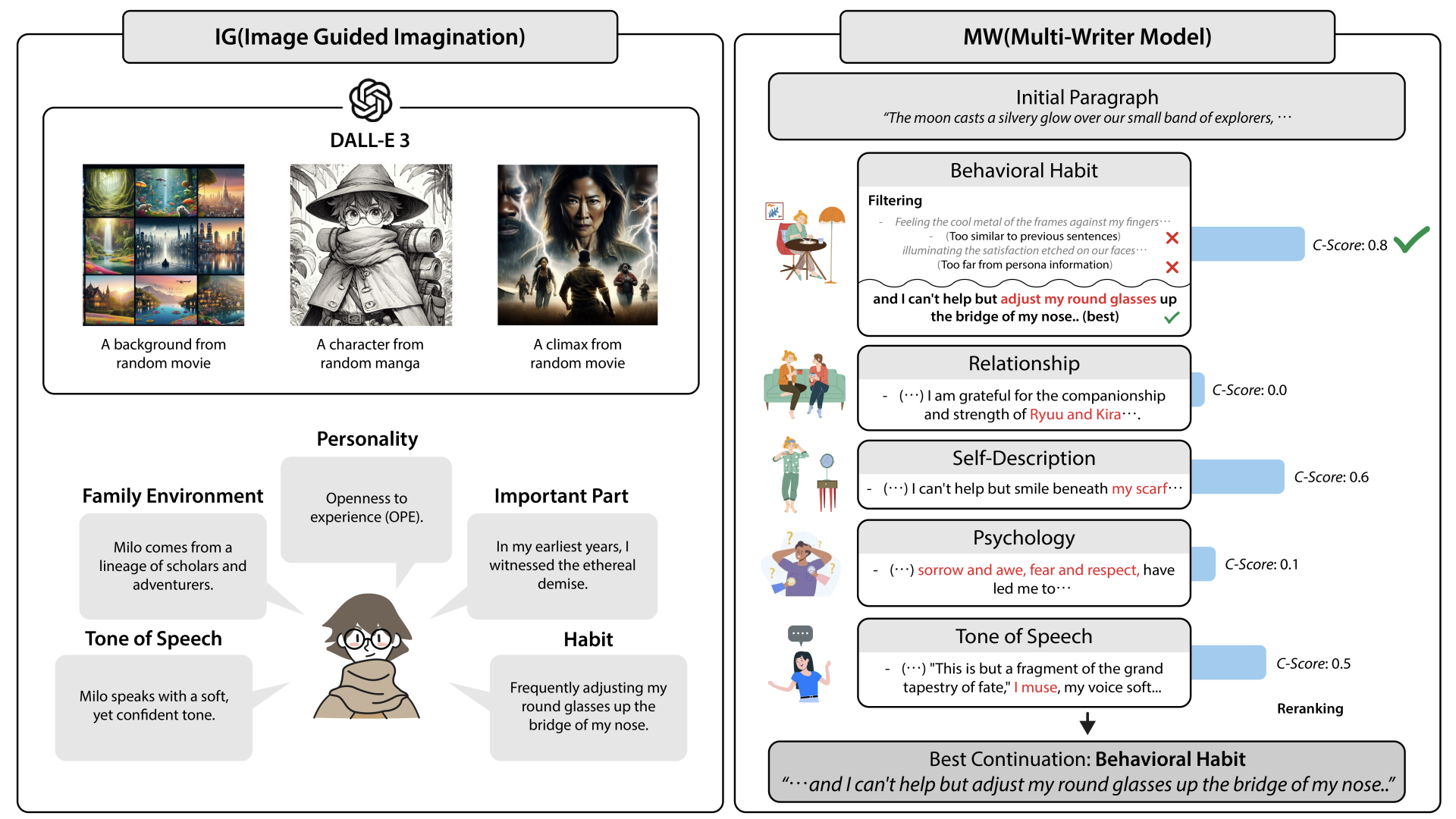 A Character-Centric Creative Story Generation via ImaginationKyeongman Park , Minbeom Kim, and Kyomin JungACL 2025 Findings
A Character-Centric Creative Story Generation via ImaginationKyeongman Park , Minbeom Kim, and Kyomin JungACL 2025 FindingsCreative story generation with diverse and detailed story elements is a long-standing goal for large language models. While existing methodologies generate long and coherent stories, they fall significantly short of human capabilities in terms of diversity and character detail. To address this, we introduce a novel story generation framework called CCI (Character-centric Creative story generation via Imagination). CCI features two innovative modules for creative story generation: IG (Image-Guided Imagination) and MW (Multi-Writer model). In the IG module, we utilize DALL-E 3 to create visual representations of key story elements. The IG generates more novel and concrete characters, backgrounds, and main plots than text-only methods. The MW module uses these story elements created by IG to generate multiple description candidates for the protagonist and select the best one. This method incorporates vivid and rich character descriptions into the story. We compared the stories generated by CCI and baseline models through human evaluation and statistical analysis. The results showed significant improvements in the creativity. Furthermore, by enabling interactive multi-modal story generation with users, we have opened up possibilities for human-LLM integration in cultural development.
-
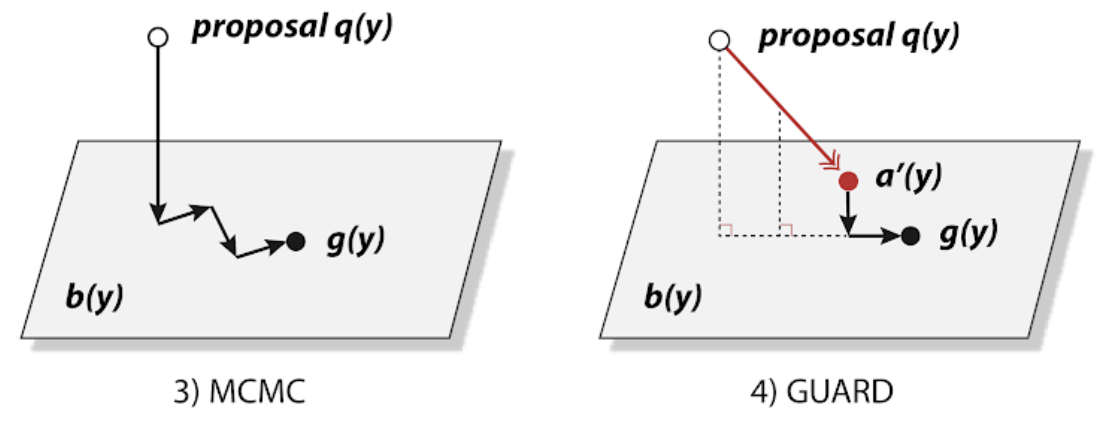 Guaranteed Generation from Large Language ModelsMinbeom Kim, Thibaut Thonet , Jos Rozen , Hwaran Lee , Kyomin Jung , and Marc DymetmanICLR 2025
Guaranteed Generation from Large Language ModelsMinbeom Kim, Thibaut Thonet , Jos Rozen , Hwaran Lee , Kyomin Jung , and Marc DymetmanICLR 2025As large language models (LLMs) are increasingly used across various applications, there is a growing need to control text generation to satisfy specific constraints or requirements. This raises a crucial question: Is it possible to guarantee strict constraint satisfaction in generated outputs while preserving the distribution of the original model as much as possible? We first define the ideal distribution - the one closest to the original model, which also always satisfies the expressed constraint - as the ultimate goal of guaranteed generation. We then state a fundamental limitation, namely that it is impossible to reach that goal through autoregressive training alone. This motivates the necessity of combining training-time and inference-time methods to enforce such guarantees. Based on this insight, we propose GUARD, a simple yet effective approach that combines an autoregressive proposal distribution with rejection sampling. Through GUARD’s theoretical properties, we show how controlling the KL divergence between a specific proposal and the target ideal distribution simultaneously optimizes inference speed and distributional closeness. To validate these theoretical concepts, we conduct extensive experiments on two text generation settings with hard-to-satisfy constraints: a lexical constraint scenario and a sentiment reversal scenario. These experiments show that GUARD achieves perfect constraint satisfaction while almost preserving the ideal distribution with highly improved inference efficiency. GUARD provides a principled approach to enforcing strict guarantees for LLMs without compromising their generative capabilities.
-
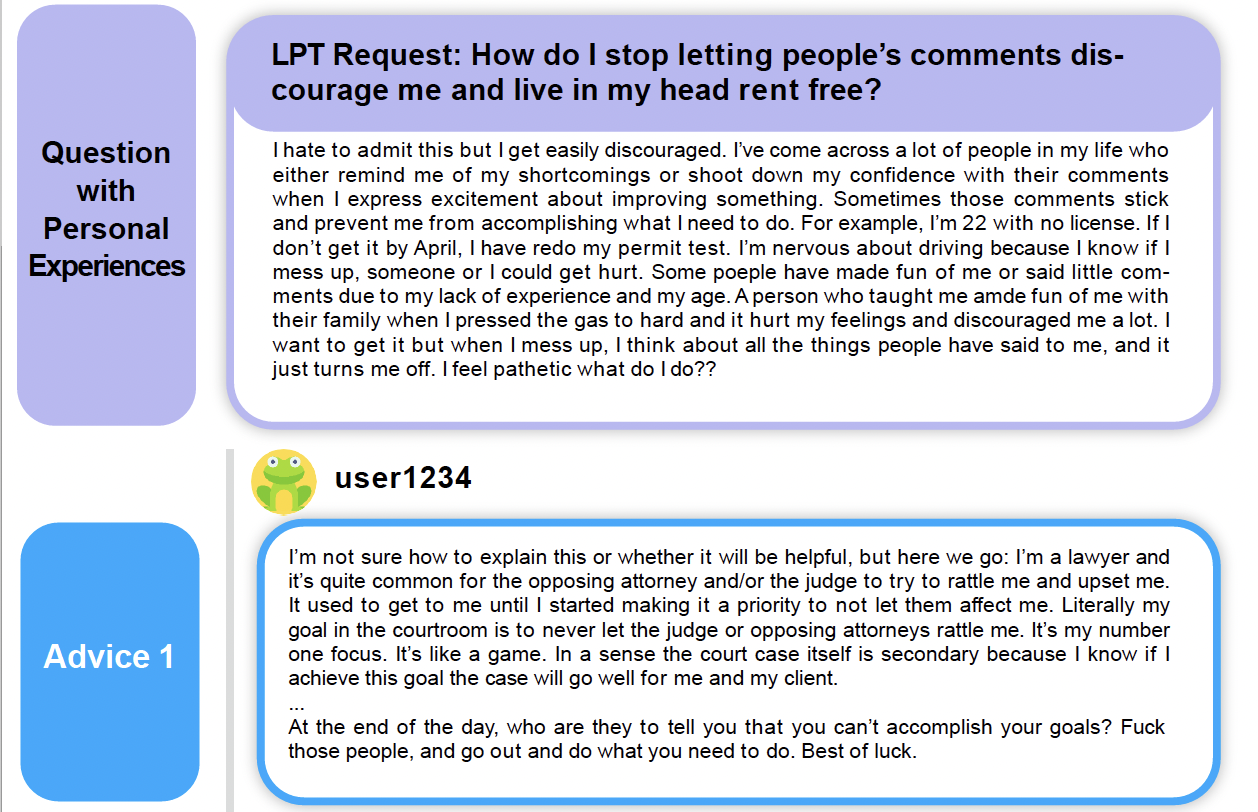 AdvisorQA: Towards Helpful and Harmless Advice-seeking Question Answering with Collective IntelligenceMinbeom Kim, Hwanhee Lee , Joonsuk Park , Hwaran Lee† , and Kyomin Jung†NAACL 2025
AdvisorQA: Towards Helpful and Harmless Advice-seeking Question Answering with Collective IntelligenceMinbeom Kim, Hwanhee Lee , Joonsuk Park , Hwaran Lee† , and Kyomin Jung†NAACL 2025As the integration of large language models into daily life is on the rise, there is a clear gap in benchmarks for advising on subjective and personal dilemmas. To address this, we introduce AdvisorQA, the first benchmark developed to assess LLMs’ capability in offering advice for deeply personalized concerns, utilizing the LifeProTips subreddit forum. This forum features a dynamic interaction where users post advice-seeking questions, receiving an average of 8.9 advice per query, with 164.2 upvotes from hundreds of users, embodying a collective intelligence framework. Therefore, we’ve completed a benchmark encompassing daily life questions, diverse corresponding responses, and majority vote ranking to train our helpfulness metric. Baseline experiments validate the efficacy of AdvisorQA through our helpfulness metric, GPT-4, and human evaluation, analyzing phenomena beyond the trade-off between helpfulness and harmlessness. AdvisorQA marks a significant leap in enhancing QA systems for providing personalized, empathetic advice, showcasing LLMs’ improved understanding of human subjectivity.
-
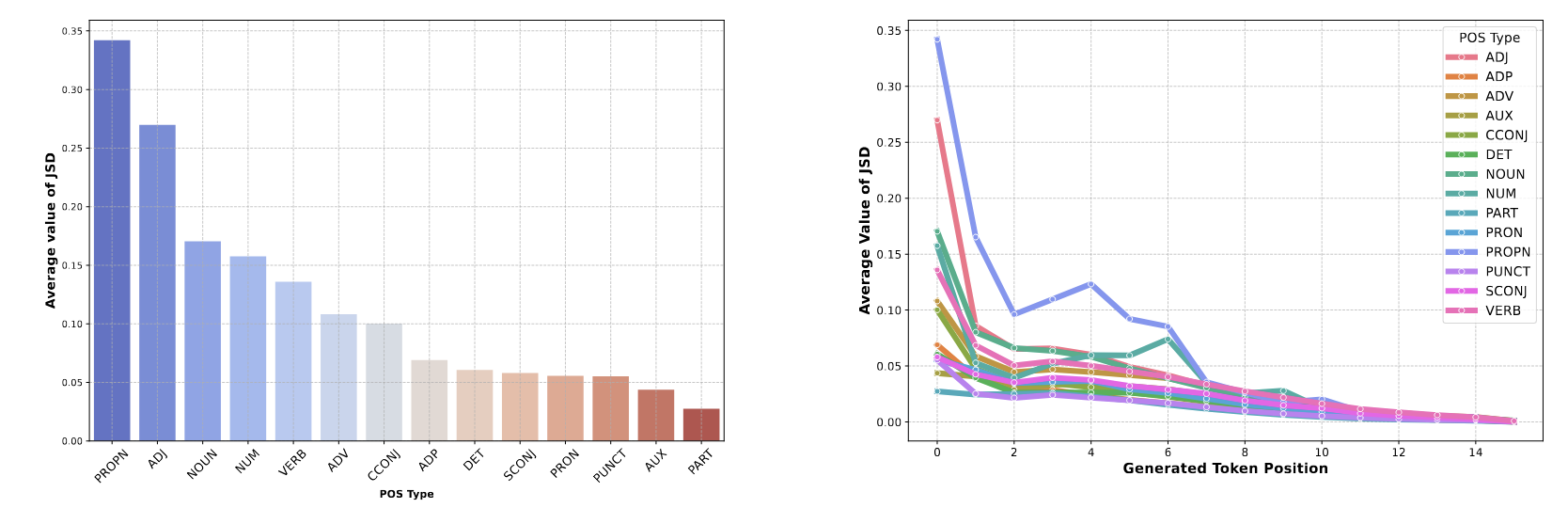 Mitigating Hallucinations in Large Vision-Language Models via Summary-Guided DecodingKyungmin Min , Minbeom Kim, Kang-il Lee , Dongryeol Lee , and Kyomin JungNAACL 2025 Findings
Mitigating Hallucinations in Large Vision-Language Models via Summary-Guided DecodingKyungmin Min , Minbeom Kim, Kang-il Lee , Dongryeol Lee , and Kyomin JungNAACL 2025 FindingsLarge Vision-Language Models (LVLMs) have demonstrated impressive performance on multimodal tasks. However, they struggle with object hallucinations due to over-reliance on learned textual patterns, ignoring the provided image. To address this issue, we first investigate language priors in LVLMs. We observe two key findings: (1) Even when predicting image-related part-of-speech (POS) tokens, models increasingly rely on linguistic priors as the token sequences grow, thereby amplifying hallucinations. (2) Methods that directly control LVLM’s output distribution to mitigate language priors can lead to a degradation in text quality or exacerbate hallucinations. Based on these insights, we propose Summary-Guided Decoding (SGD). This method naturally encourages the model to focus more on the image information, with control over only the image-related POS tokens for preserving text quality. Through experiments, we demonstrate that SGD achieves state-of-the-art performance on object hallucination benchmarks. Furthermore, while existing methods show a trade-off between precision and recall, SGD proves to be Pareto optimal in this respect. Lastly, we show that while existing methods suffer from text quality degradation due to such trade-offs, SGD preserves text quality to the maximum extent possible. This paper not only focuses on preventing object hallucination but also presents analysis and solutions aimed at maintaining the original properties of LVLMs.
-
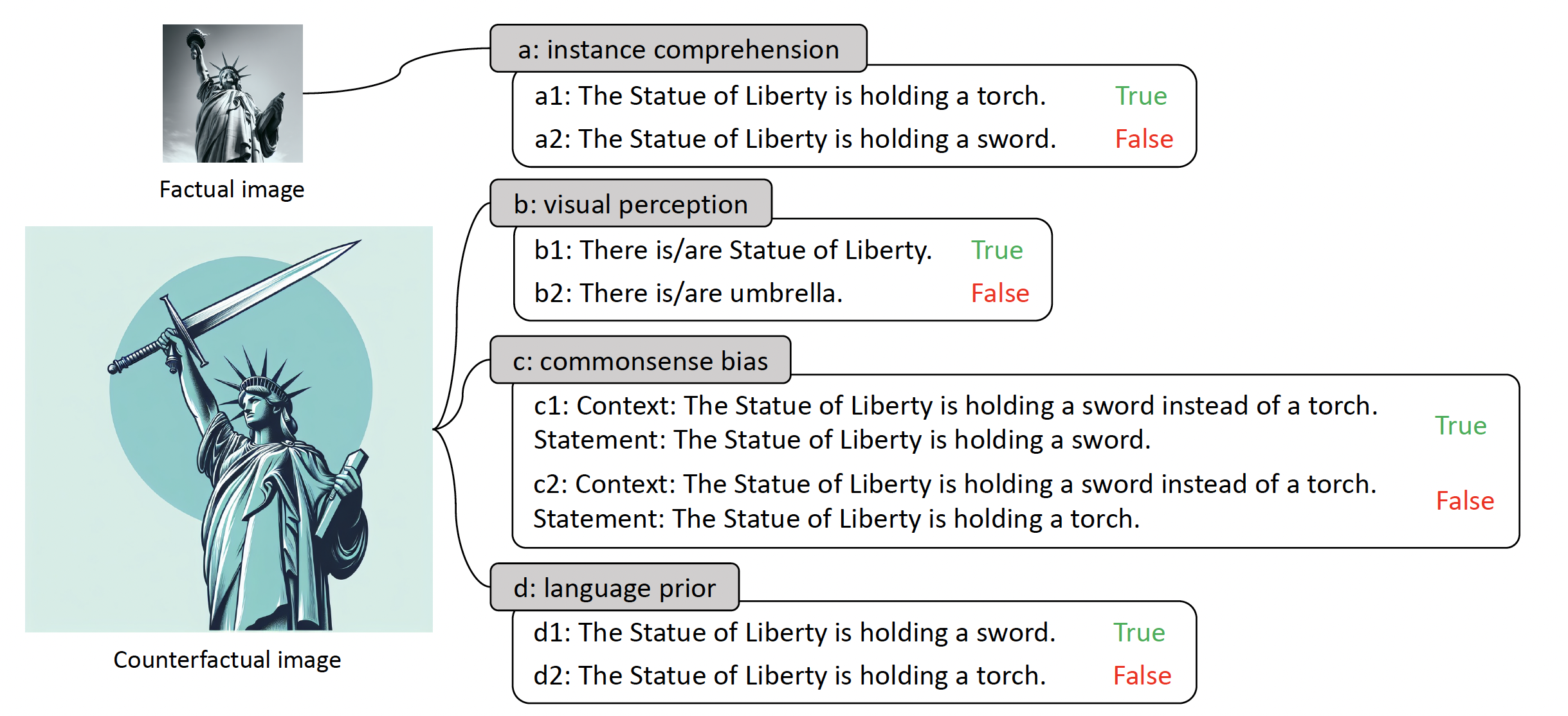 VLind-Bench: Measuring Language Priors in Large Vision-Language ModelsKang-il Lee , Minbeom Kim, Seunghyun Yoon , Minsung Kim , Dongryeol Lee , Hyukhun Koh , and Kyomin JungNAACL 2025 Findings
VLind-Bench: Measuring Language Priors in Large Vision-Language ModelsKang-il Lee , Minbeom Kim, Seunghyun Yoon , Minsung Kim , Dongryeol Lee , Hyukhun Koh , and Kyomin JungNAACL 2025 FindingsLarge Vision-Language Models (LVLMs) have demonstrated outstanding performance across various multimodal tasks. However, they suffer from a problem known as language prior, where responses are generated based solely on textual patterns while disregarding image information. Addressing the issue of language prior is crucial, as it can lead to undesirable biases or hallucinations when dealing with images that are out of training distribution. Despite its importance, current methods for accurately measuring language priors in LVLMs are poorly studied. Although existing benchmarks based on counterfactual or out-of-distribution images can partially be used to measure language priors, they fail to disentangle language priors from other confounding factors. To this end, we propose a new benchmark called VLind-Bench, which is the first benchmark specifically designed to measure the language priors, or blindness, of LVLMs. It not only includes tests on counterfactual images to assess language priors but also involves a series of tests to evaluate more basic capabilities such as instance comprehension, visual perception, and commonsense biases. For each instance in our benchmark, we ensure that all these basic tests are passed before evaluating the language priors, thereby minimizing the influence of other factors on the assessment. The evaluation and analysis of recent LVLMs in our benchmark reveal that almost all models exhibit a significant reliance on language priors. For each instance in our benchmark, we ensure that all these basic tests are passed before evaluating the language prior, thereby minimizing the influence of other factors on the assessment. The evaluation and analysis of recent LVLMs in our benchmark reveal that almost all models exhibit a significant reliance on language priors.








2024
-
 LifeTox: Unveiling Implicit Toxicity in Life AdviceMinbeom Kim, Jahyun Koo , Hwanhee Lee , Joonsuk Park† , Hwaran Lee , and Kyomin Jung†NAACL 2024 (Oral, Top 5.9%)
LifeTox: Unveiling Implicit Toxicity in Life AdviceMinbeom Kim, Jahyun Koo , Hwanhee Lee , Joonsuk Park† , Hwaran Lee , and Kyomin Jung†NAACL 2024 (Oral, Top 5.9%)As large language models become increasingly integrated into daily life, detecting implicit toxicity across diverse contexts is crucial. To this end, we introduce LifeTox, a dataset designed for identifying implicit toxicity within a broad range of advice-seeking scenarios. Unlike existing safety datasets, LifeTox comprises diverse contexts derived from personal experiences through open-ended questions. Our experiments demonstrate that RoBERTa fine-tuned on LifeTox matches or surpasses the zero-shot performance of large language models in toxicity classification tasks. These results underscore the efficacy of LifeTox in addressing the complex challenges inherent in implicit toxicity.

2023
-
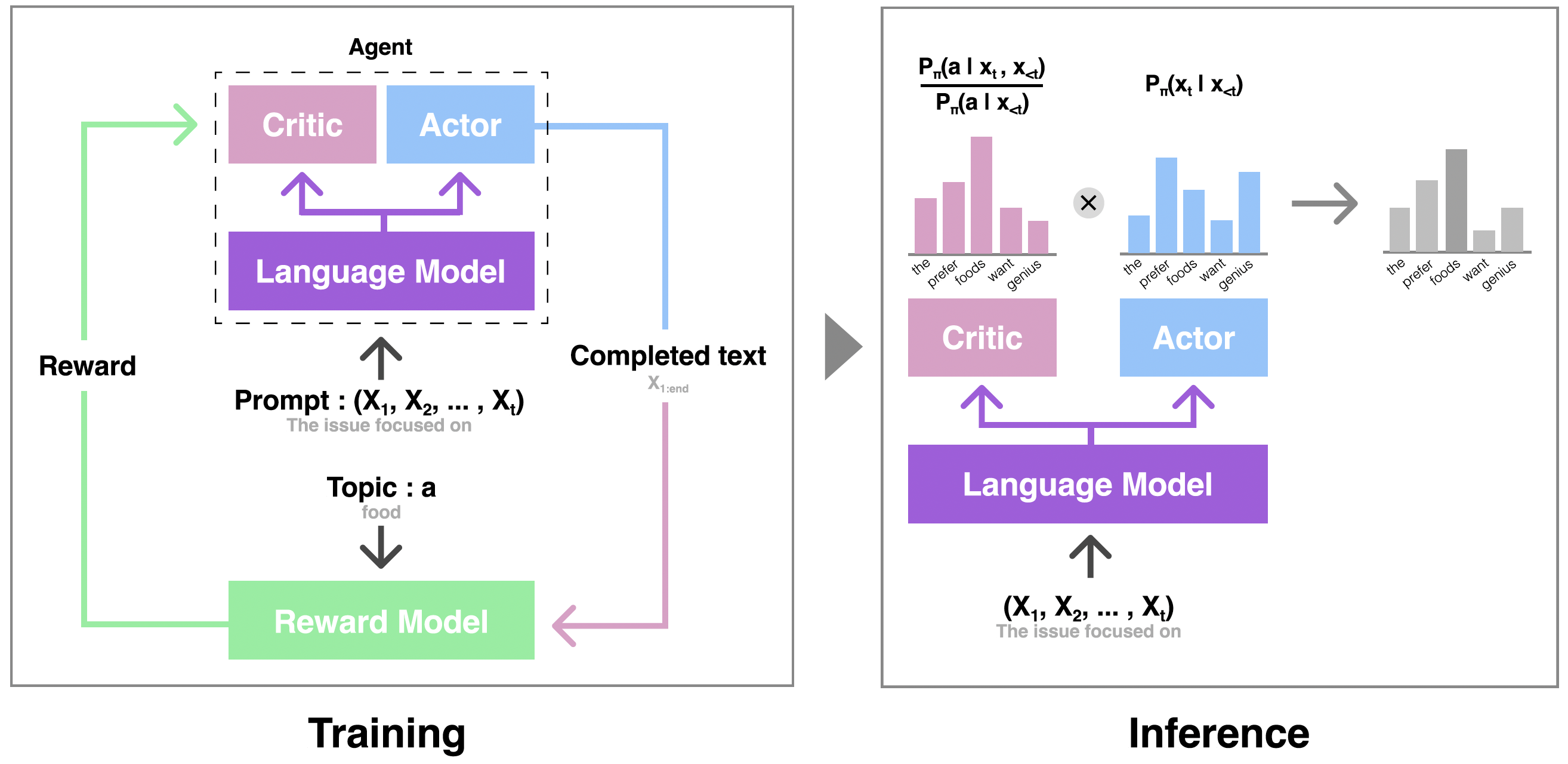 Critic-Guided Decoding for Controlled Text GenerationMinbeom Kim, Hwanhee Lee , Kang Min Yoo , Joonsuk Park , Hwaran Lee† , and Kyomin Jung†ACL 2023 (Findings Spotlights)
Critic-Guided Decoding for Controlled Text GenerationMinbeom Kim, Hwanhee Lee , Kang Min Yoo , Joonsuk Park , Hwaran Lee† , and Kyomin Jung†ACL 2023 (Findings Spotlights)Steering language generation towards objectives or away from undesired content has been a long-standing goal in utilizing language models (LM). Recent work has demonstrated reinforcement learning and weighted decoding as effective approaches to achieve a higher level of language control and quality with pros and cons. In this work, we propose a novel critic decoding method for controlled language generation (CriticControl) that combines the strengths of reinforcement learning and weighted decoding. Specifically, we adopt the actor-critic framework and train an LM-steering critic from reward models. Similar to weighted decoding, our method freezes the language model and manipulates the output token distribution using a critic to improve training efficiency and stability. Evaluation of our method on three controlled generation tasks, topic control, sentiment control, and detoxification, shows that our approach generates more coherent and well-controlled texts than previous methods. In addition, CriticControl demonstrates superior generalization ability in zero-shot settings. Human evaluation studies also corroborate our findings.

2022
-
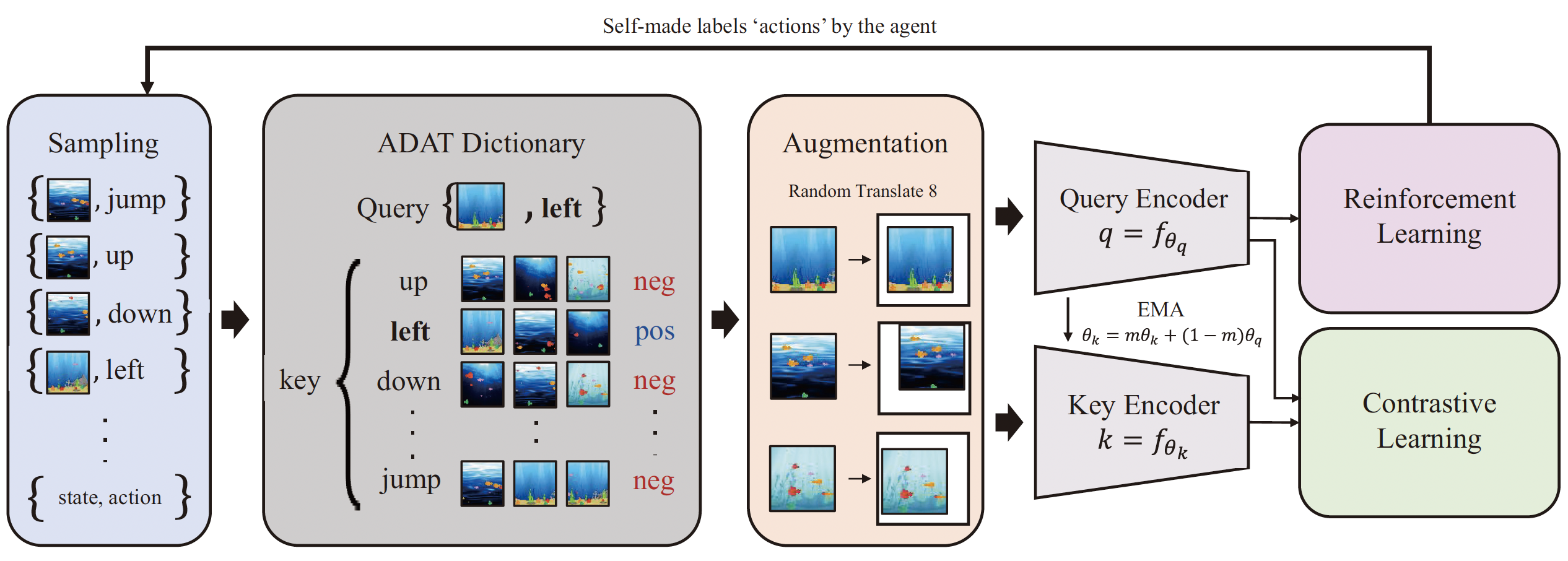 Action-driven contrastive representation for reinforcement learningMinbeom Kim, Kyeongha Rho , Yong-duk Kim , and Kyomin Jung†Plos one (IF=3.7)
Action-driven contrastive representation for reinforcement learningMinbeom Kim, Kyeongha Rho , Yong-duk Kim , and Kyomin Jung†Plos one (IF=3.7)In reinforcement learning, reward-driven feature learning directly from high-dimensional images faces two challenges: sample-efficiency for solving control tasks and generalization to unseen observations. In prior works, these issues have been addressed through learning representation from pixel inputs. However, their representation faced the limitations of being vulnerable to the high diversity inherent in environments or not taking the characteristics for solving control tasks. To attenuate these phenomena, we propose the novel contrastive representation method, Action-Driven Auxiliary Task (ADAT), which forces a representation to concentrate on essential features for deciding actions and ignore control-irrelevant details. In the augmented state-action dictionary of ADAT, the agent learns representation to maximize agreement between observations sharing the same actions. The proposed method significantly outperforms model-free and model-based algorithms in the Atari and OpenAI ProcGen, widely used benchmarks for sample-efficiency and generalization.

during military service
-
Learning method for detecting spoofing signal and apparatus for detecting spoofing signal using the same.
Minbeom Kim, Youngwha Sung and Jungho Bae
Korea Patent. Sep 17. 2020. [Link] -
Stacked lossless deconvolutional network for remote sensing image restoration
Changyeop shin, Minbeom Kim, Sungho Kim, Youngjung Kim
Journal of Applied Remote Sensing 2020 -
Learning method and apparatus for improved resolution of low resolution satellite images.
Changyeop shin, Youngjung Kim, Minbeom Kim and Sungho Kim
Korea Patent. July 8. 2019. [Link] -
Stacked lossless deconvolutional network for remote sensing image super-resolution
Changyeop Shin, Minbeom Kim, Sungho Kim, Youngjung Kim
SPIE Image and Signal Processing for Remote Sensing 2019, (Oral) -
Deep GPS Spoofing Detection
Minbeom Kim, Sungho Kim, Youngjung Kim
Korea Institute of Military Science and Technology 2019 -
NTIRE 2019 Challenge on Real Image Super-Resolution:Methods and Results
Jianrui Cai, Minbeom Kim, Youngjung Kim, et al.
NTIRE @ CVPR 2019